NUMCODE
OPEN PROTOCOL
A Universal Numeric Protocol for Human Language
NumCode encodes text from any language as numeric sequences. Each word receives a unique ID based on its real frequency of use, extracted from millions of authentic texts. That ID can be transmitted as binary, rendered as a geometric ideogram, or — in the future — projected as a pattern of light. It is not AI. It is not a translator. It is not lossy compression. It is a new layer between meaning and transmission.
NumCode 26185 988 30 159 550 25 34290 8026 1 286 690 6458 9 2534 907 329 21 111 393 4139 4 272 2 13729 30 4349 4 10397 4611 1 19 907 62 34 10136 25 9439 2 8587 25 9 12294 190318 2 67 8 3 851 9454 25 9 3454 4 618 1 18 13 36 6605 1 18 13 36 9 7003 1 18 13 36 86113 11495 1 18 13 9 82 5305 184 1601 5 4332 1


80%
Compression
vs UTF-8
100%
Round-trip
Accuracy
6
Languages
Supported
27M+
Tokens in
Dictionaries
How It Works
From Text to Numbers to Light
TEXT
NUMCODE IDs


IDEOGRAM GRID
NUMCODE IDs
TEXT
Tokenize — Input text is split into individual tokens.
Encode — Each token is looked up in a native-language frequency dictionary. The most common words get the lowest IDs.
Suffix — Each ID carries a 3-bit prefix indicating length. Special codes use prefix 111 followed by a type nibble: n (number), im (image), so (sound), r (repetition), enc (encrypted), bin (binary), L (letter-by-letter fallback).
Transmit — The ID sequence is sent as compact binary (80% smaller than UTF-8) or mapped to a 10×20 geometric grid.
Decode — The receiver loads the same dictionary and recovers the original text. 100% accuracy.
The Grid
The Constellation Grid: 8 Quadrants, One Concept
Each numeric ID maps to a stroke pattern drawn across an 8-quadrant grid arranged in 2 rows × 4 columns. Each quadrant has 10 positions (digits 0–9) in a 2×5 internal layout.
The first digit of the ID maps to Quadrant 0, the second to Quadrant 1, and so on. Points are connected with straight lines, creating a unique geometric constellation for every word.
Lower IDs produce simpler shapes: "the" (ID 3) is a single dash. "water" (ID 383) is a three-point stroke. "constellation" (ID 24891) is a five-point form.
The grid is sacred. It never changes. All non-dictionary content (numbers, images, sound, encryption) routes through the special code channel without touching the grid.


COMPRESSION RESULTS
Hybrid v3 Protocol Results — February 2026
Results correspond to the binary wire format of NumCode IDs under the defined tokenization and encoding settings. Ideogram (visual) encoding has different size characteristics depending on grid resolution.
Short phrase
Savings: 77%
English paragraph
Savings: 76%
Literary text
Savings: 80%
Average: 9.7 bits per token
IDs 251–1000 use block encoding (11 bits)
IDs 10–250 encoded as direct bytes (8 bits)
100% Coverage: Letter-by-Letter Fallback
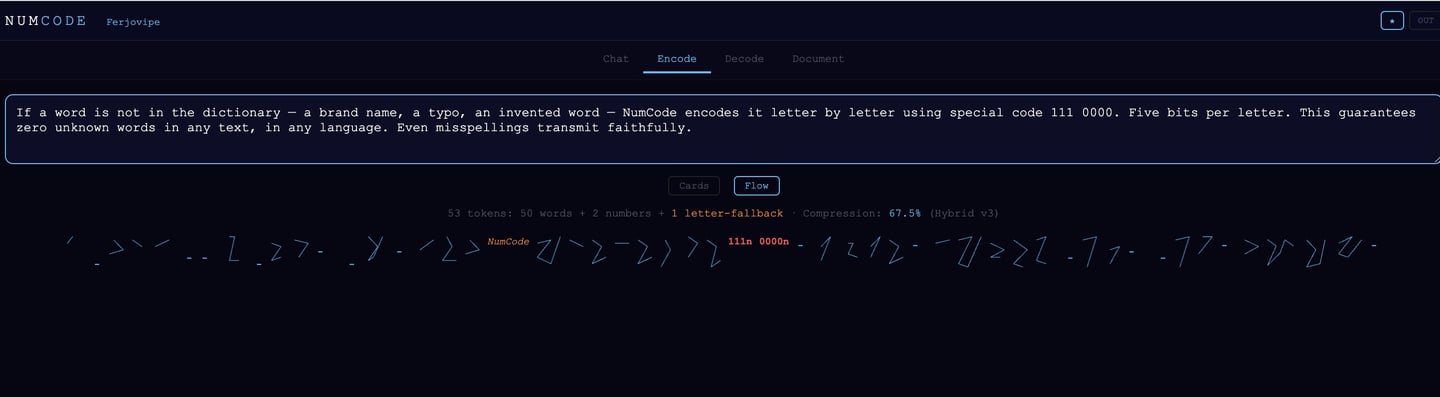
If a word is not in the dictionary — a brand name, a typo, an invented word — NumCode encodes it letter by letter using special code 111 0000. Five bits per letter. This guarantees zero unknown words in any text, in any language. Even misspellings transmit faithfully.
Number Encoding
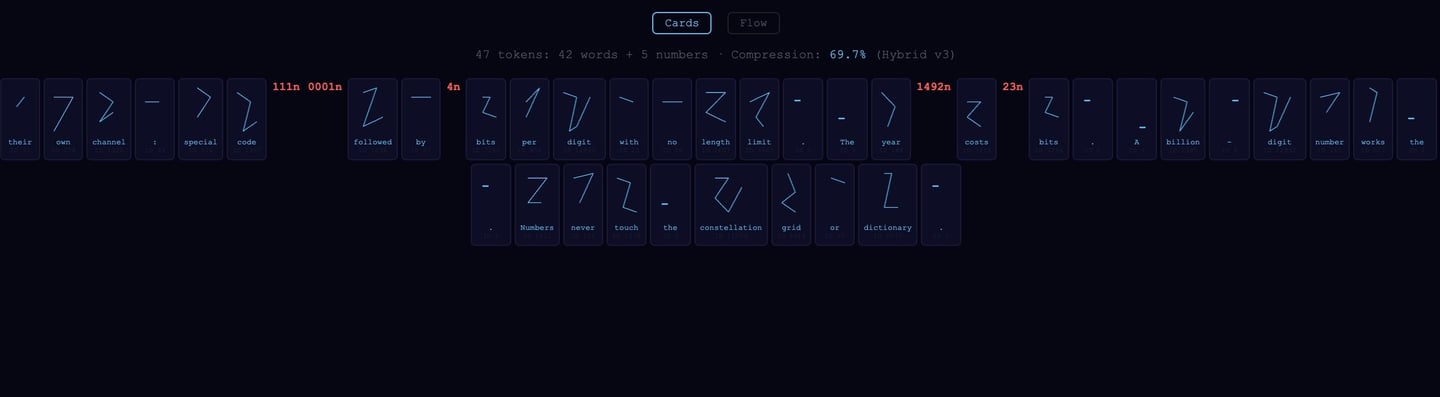
Numbers use their own channel: special code 111 0001 followed by 4 bits per digit with no length limit. The year 1492 costs 23 bits. A billion-digit number works the same way. Numbers never touch the constellation grid or dictionary.
LANGUAGES
Six Languages. Native Dictionaries. No Machine Translation.
Every dictionary is built exclusively from real human text — Wikipedia articles, movie subtitles, web content. No synthetic data. No machine translations. Each language has its own independent frequency ranking: ID 383 means "agua" in Spanish and a completely different word in English.
Español (ES)
7,000,000 tokens
Wikipedia ES
OpenSubtitles ES /mc4
English (EN)
9,618,282 tokens
Wikipedia EN
OpenSubtitles EN
العربية (AR)
4,800,903 tokens
OpenSubtitles AR
Wikipedia AR
OpenSubtitles ZH
mC4 ZH
2,271,472 tokens
中文 (ZH)
Português (PT)
1,777,661 tokens
Wikipedia PT
OpenSubtitles PT
Français (FR)
1,710,392 tokens
Wikipedia FR
OpenSubtitles FR
THE VISION
The Road from Numbers to Photons
Words become numbers. Frequency determines ID assignment.
Six languages. Millions of authentic tokens per dictionary.
Constellation Grid ✓ DONE — 8-quadrant sacred grid, unique visual glyph per word
Hybrid v3 Protocol ✓ DONE — Up to 80% compression, 9.7 bits/token average
Multilingual Messenger ✓ DONE — 6 languages live at numcode.netlify.app
Letter Fallback ✓ DONE — 100% coverage, zero unknowns
Geometric Encryption → IN PROGRESS — Grid permutation as cipher key
The ideogram grid becomes a physical mask. A continuous-wave laser projects through it. One flash = one complete concept. Theoretical latency: sub-30 picoseconds per symbol.
Visual objects composed of their own semantic definition. An image of water where every pixel contains the ID for "water." Information where form and content are the same thing.
WHAT NUMCODE IS NOT
Not a translator. Each language encodes and decodes independently using its own dictionary. IDs are per-language, not universal concept identifiers.
Not an AI model. No neural networks. No training. No generation. Deterministic lookup tables built from real human text.
Not lossy compression. Every token in the canonical stream is recovered exactly. 100% round-trip accuracy on the normalized token sequence.


GET STARTED
NumCode is open source under the MIT License. Dictionaries are released for research and non-commercial use.
NumCode · Patent Pending · Created by Fernando · Madrid, Spain · 2026 Part of THE HIVE Project — aithehive.com
contact@aithehive.com